
HEROIC Technology
DarkHive Engine
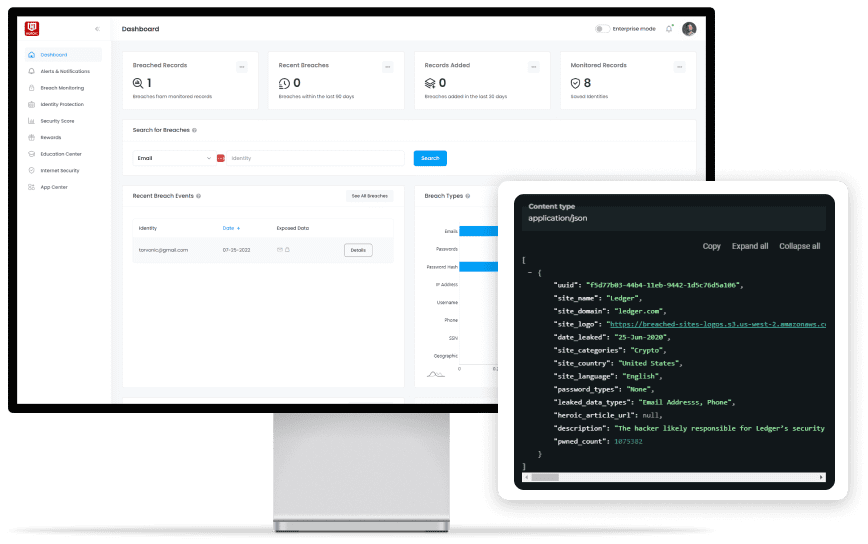
The continuous engine behind every HEROIC product. It acquires raw data from the open, deep, and dark web, cleans it, ingests it, and makes it accessible. One pipeline. One product.
Stage 01
Acquire the raw data.
Continuous collection across the open, deep, and dark web.
DarkHive runs crawlers, scrapers, and operator-led collection across a continuously expanding range of sources spanning the open, deep, and dark web. Restricted sources behind authentication or invite-only environments are handled manually by our intelligence team.
- Hundreds of independent sources across the open, deep, and dark web
- Operator-led acquisition for restricted sources
- Source and confidence tracked from first byte
Stage 02
Clean and normalize.
Normalize, validate, dedupe, attach provenance.
Raw data is messy. Cleaning normalizes formats, validates fields, dedupes across sources with hash matching, and attaches provenance, timestamp, and a confidence score to every survivor.
- Schema normalization across all source formats
- Cross-source deduplication and merging
- Per-record provenance, timestamp, and confidence
Stage 03
Ingest and index.
Indexed into hardened storage with schema and lineage.
Cleaned records land in a columnar store tuned for identifier pivots. A single shared schema feeds every HEROIC product, with end-to-end lineage from acquisition to query.
- Columnar store tuned for identifier pivots
- Single schema, shared across all HEROIC products
- End-to-end lineage from acquisition to query
Stage 04
Access across every product.
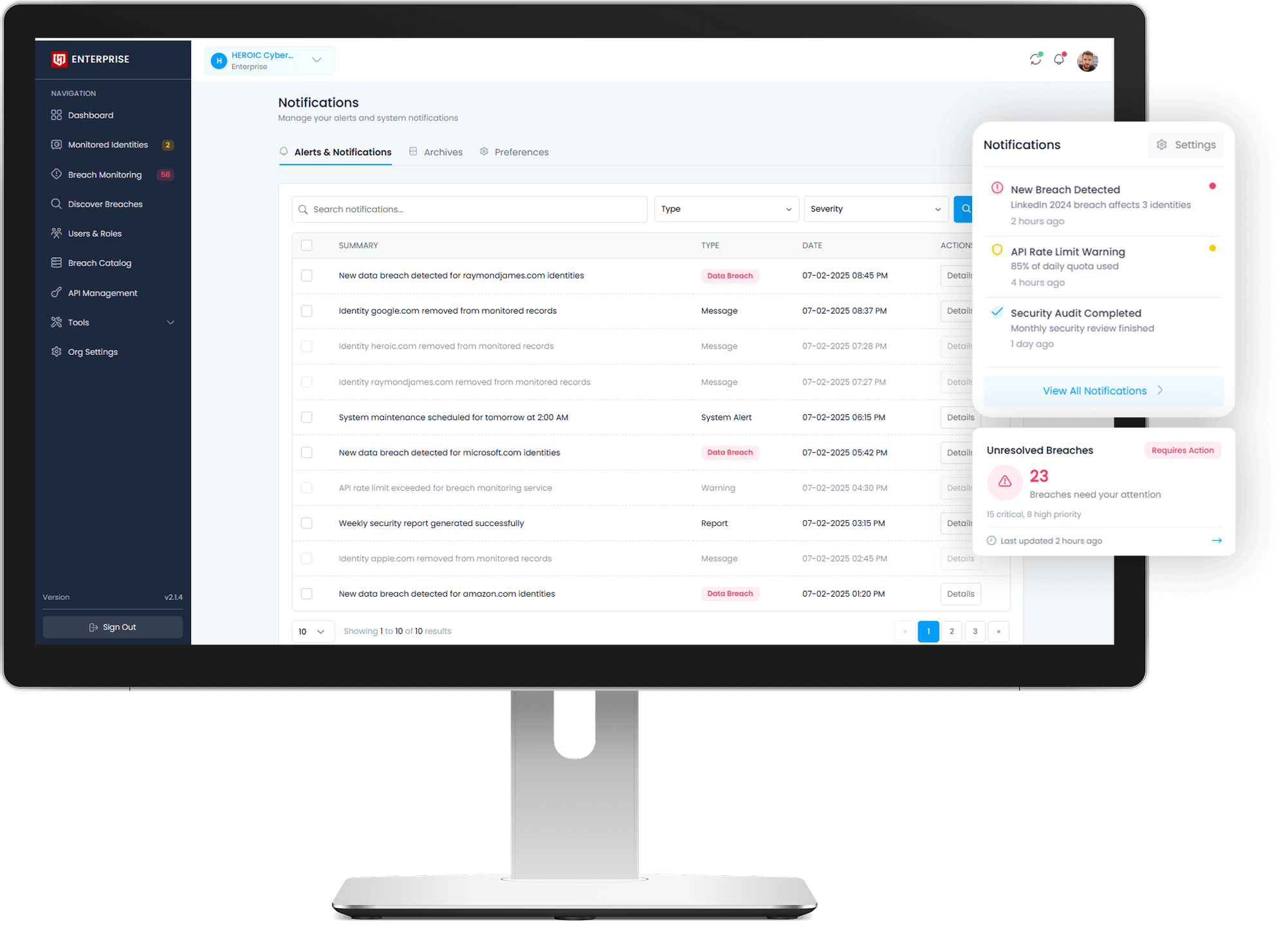
Surfaced through every HEROIC product and the API.
The same engine powers DarkWatch, Guardian, and Cyberlytics, and is available via the HEROIC API. Operator workflows include real-time search, standing watchlists, programmatic enrichment, and scheduled exports.
- Real-time search and pivot
- Standing watchlists with instant alerting
- Programmatic access via HEROIC API and exports
Source streams
Where the data comes from.
Data flows in continuously from hundreds of sources across the open, deep, and dark web.
What you can do
Built for operators.
DarkHive is designed to be queried, monitored, enriched, and exported. Pull what you need into your stack, or run inside ours.
- Search — Pivot across emails, domains, usernames, IPs, and credentials in milliseconds.
- Monitor — Standing watchlists fire alerts the moment a matching record is ingested.
- Enrich — Join records against identity, asset, and threat context to build full pictures.
- Export & API — Pull what you need into your own stack via the HEROIC API or scheduled exports.
FAQ
Common questions.
Hundreds of sources across the open, deep, and dark web, spanning corporate breach dumps, infostealer logs, dark web marketplaces, aggregated combo lists, Telegram channels, and vetted research partner feeds. Every record carries its source.
Ingestion is continuous. New records become searchable across the HEROIC stack as soon as they pass cleaning and indexing. Watchlists fire alerts the moment a match lands.
Hash-based dedupe collapses redundant rows across sources into a single canonical record. Every record carries a confidence score, ingestion timestamp, and source lineage you can trace back to acquisition.
Yes. The HEROIC API gives partners and integrators direct programmatic access to the same engine that powers DarkWatch, Guardian, and Cyberlytics. See the API docs.
All of them. DarkWatch (operator workspace), Guardian (consumer identity protection), Cyberlytics (org-level analytics), and the HEROIC API. One engine, one dataset.
DarkHive operates within established threat intelligence research norms. We surface what's already been exposed publicly, on the dark web, or via partner agreements, never the underlying systems themselves. Acquisition workflows are scoped and reviewed.
/img/qr-code.png)